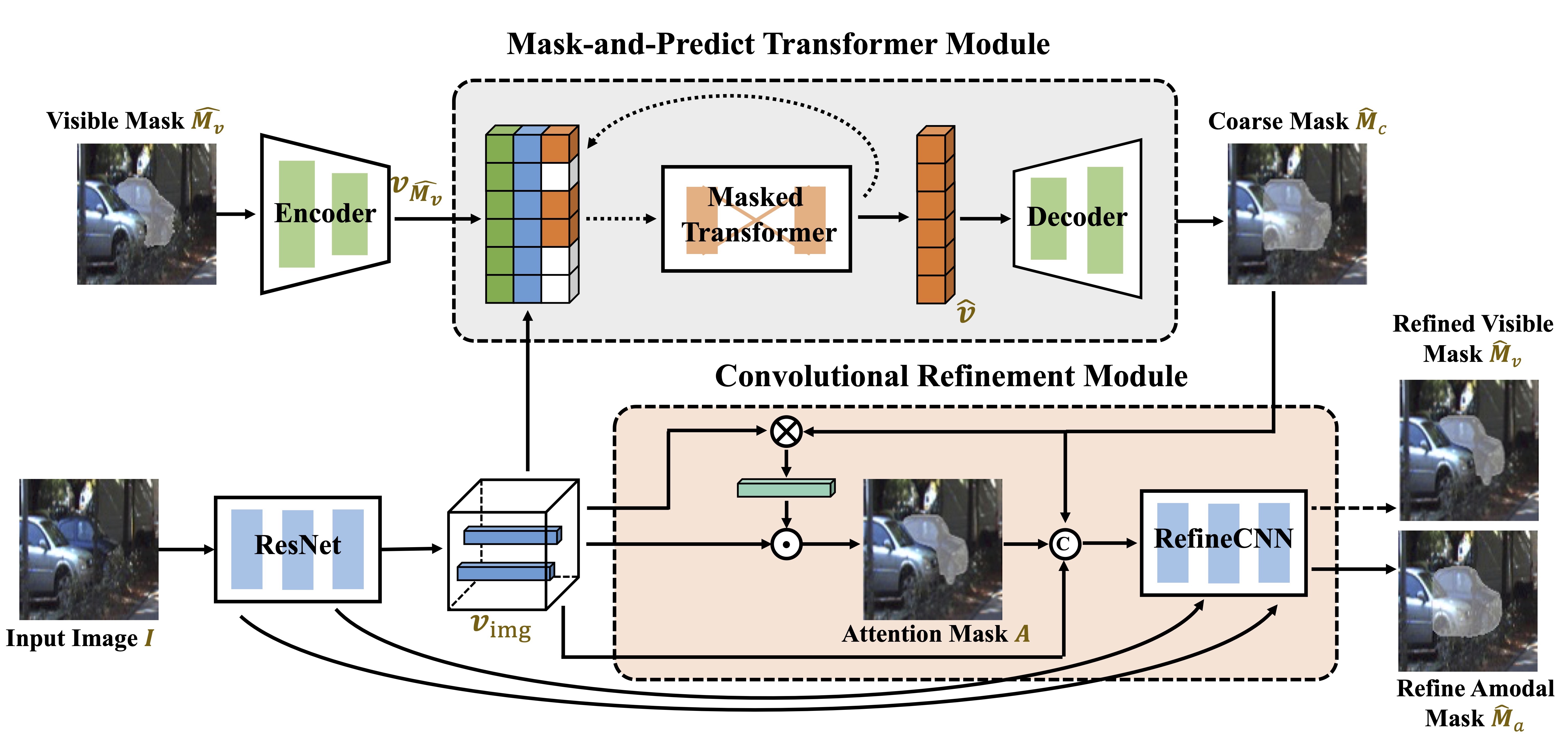
The overview of our C2F-Seg. C2F-Seg first generates a coarse mask from the visible mask and visual features via the mask-and-predict procedure with transformers. Then this coarse amodal mask is refined with a convolutional module guided by human-imitated attention on visual features of the amodal object. The learning of visible mask is used as an auxiliary task in training, while in inference we only provide an estimation of amodal mask.


