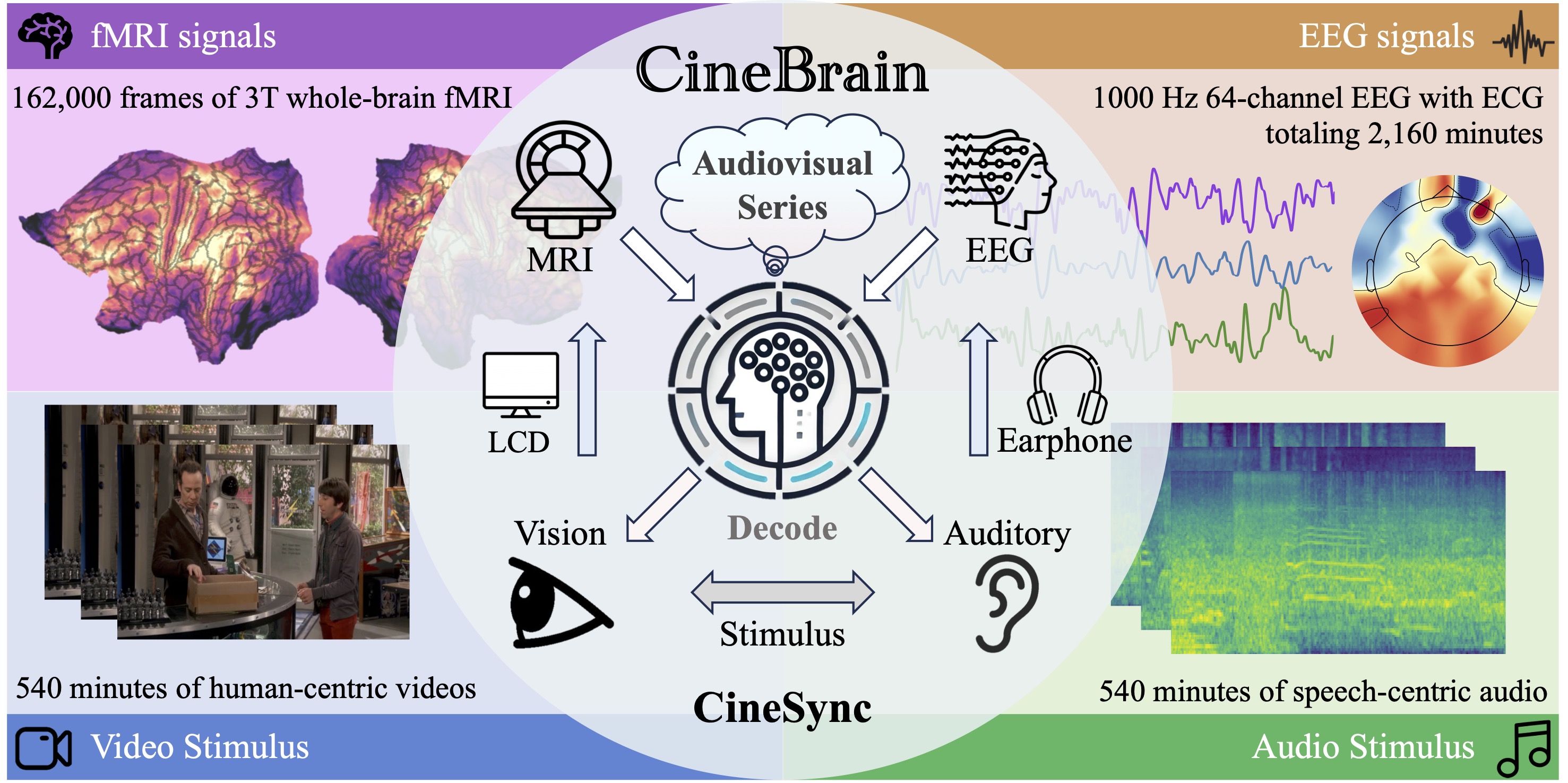
Most research decoding brain signals into images, often using them as priors for generative models, has focused only on visual content. This overlooks the brain's natural ability to integrate auditory and visual information; for instance, sound strongly influences how we perceive visual scenes. To investigate this, we propose a new task of reconstructing continuous video stimuli from multimodal brain signals recorded during audiovisual stimulation. To enable this, we introduce CineBrain, the first large-scale dataset that synchronizes fMRI and EEG during audiovisual viewing, featuring six hours of The Big Bang Theory episodes for cross-modal alignment. We also conduct the first systematic exploration of combining fMRI and EEG for video reconstruction and present CineSync, a framework for reconstructing dynamic video using a Multi-Modal Fusion Encoder and a Neural Latent Decoder. CineSync achieves state-of-the-art performance in dynamic reconstruction, leveraging the complementary strengths of fMRI and EEG to improve visual fidelity. Our analysis shows that auditory cortical activations enhance decoding accuracy, highlighting the role of auditory input in visual perception.
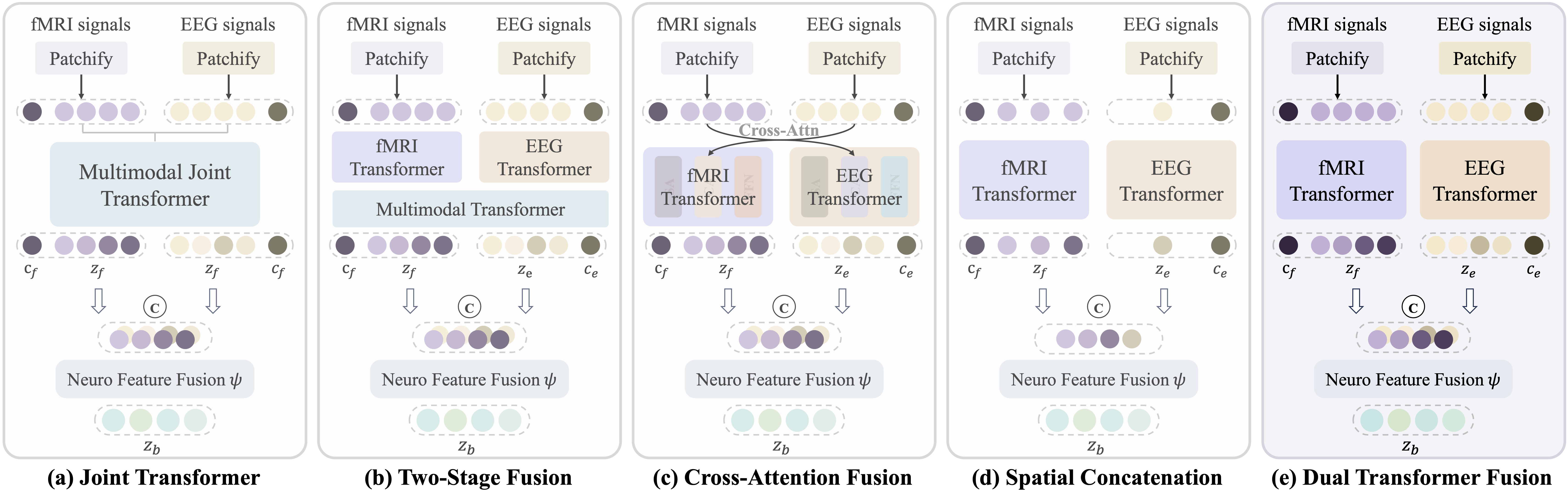
Architectural exploration for integrating fMRI and EEG. We compare five encoder variants, each adopting a distinct fusion mechanism to integrate the complementary information from fMRI and EEG signals.
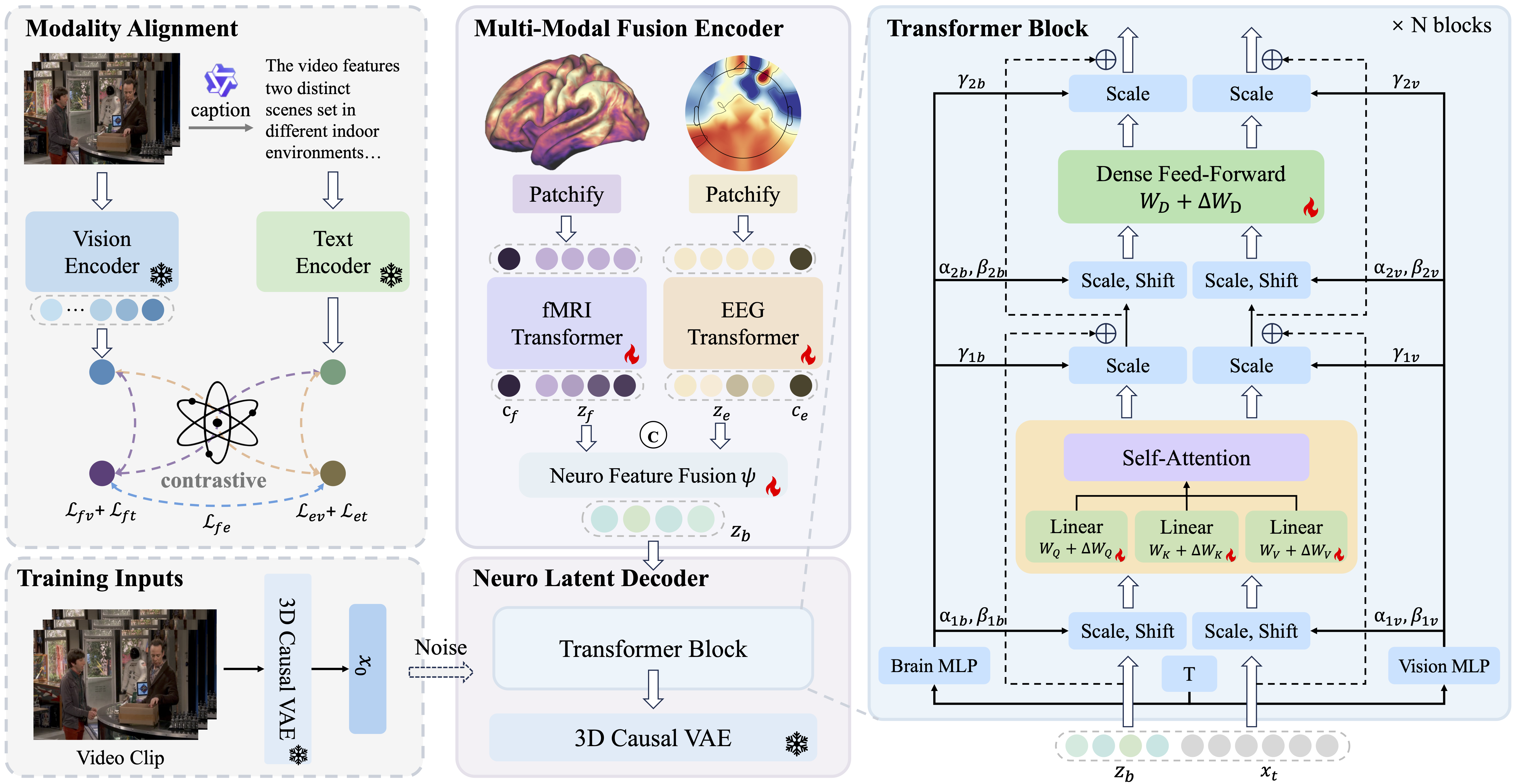
Overview of the CineSync Framework. CineSync first employs a Multimodal Fusion Encoder to extract features from fMRI and EEG data, with a modality alignment module to align these features with semantic information. Subsequently, it utilizes a LoRA-tuned neural latent decoder to reconstruct videos based on the fused brain features. Note: The gray box is used only during training.

Qualitative comparison of our method with baselines. We compare the results of CineSync, CineSync-fMRI, and CineSync-EEG with the ground truth (GT). CineSync demonstrates higher accuracy, greater temporal consistency, and improved video quality.
@misc{gao2025cinebrain,
title={CineBrain: A Large-Scale Multi-Modal Audiovisual Brain Dataset for Brain-Conditioned Video Generation},
author={Jianxiong Gao and Yichang Liu and Baofeng Yang and Jianfeng Feng and Yanwei Fu},
year={2025},
eprint={2503.06940},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2503.06940},
}